This is a written version of the talk I gave on the Cyber Social stage at InfoSecurity Europe 2026, where Konvu was named winner of the Cyber Startup Award 2026.
Finding vulnerabilities used to be the hard part. That stopped being true this year.
Anthropic's Mythos preview, shared with a small group of partners under Project Glasswing, demonstrated something the rest of the industry is about to feel: at the frontier, discovery is close to free. You point capable models at code and they surface real, exploitable conditions, at a rate no human research team can match.
The numbers were already moving before any of this shipped broadly. CVE volume has roughly tripled since 2021. At 2026's pace we are on track for around 184 published CVEs a day, up from about 55 five years ago. Sergej Epp's Zero Day Clock now measures the time from disclosure to in-the-wild exploitation in hours, not weeks.
Anthropic said the quiet part plainly in their Glasswing update: the bottleneck in fixing these bugs is the human capacity to triage. Finding is easy now. Everything downstream is not.
This is the problem we work on at Konvu, and it is worth being precise about what actually breaks.
The signal most people are misreading
Watch the bug bounty programs. curl pulled back hard on its bounty under a flood of AI-generated reports. The Linux kernel went from roughly 2 to 10 vulnerability reports a week. The reflexive read across the industry was: this is AI slop, ignore the volume.
Early on, that was partly true. It is becoming less true fast.
On a widely used open source project that runs our software to triage its inbound report stream, more than four out of five reports the system processed reproduced as genuine, exploitable issues. That is one project over one window, not a universal constant. But the direction is the point: the share of real findings in the noise is climbing, not falling.
So the signal is not "AI generates garbage." The signal is that the volume of valid findings is now permanently higher than anything your triage process was designed to absorb. Your triage capacity is the bottleneck, and it is going to stay the bottleneck.
The asymmetry that breaks the program
Here is the structural problem in one line. Finding is cheap, parallel, and automated. Fixing is expensive, sequential, and human-bottlenecked at every stage.
Walk the funnel. Scan, triage, reproduce, design the patch, test, deploy, verify. Everything after the scan has a human in the critical path. Pre-Mythos, that funnel could absorb the input rate. Dozens of criticals a month is a tractable queue.
Post-Mythos, the input rate jumps by an order of magnitude and the funnel does not change. Discovery has always outpaced remediation capacity. What is new is the size of the gap, and the speed at which it widens. That widening gap is your backlog.
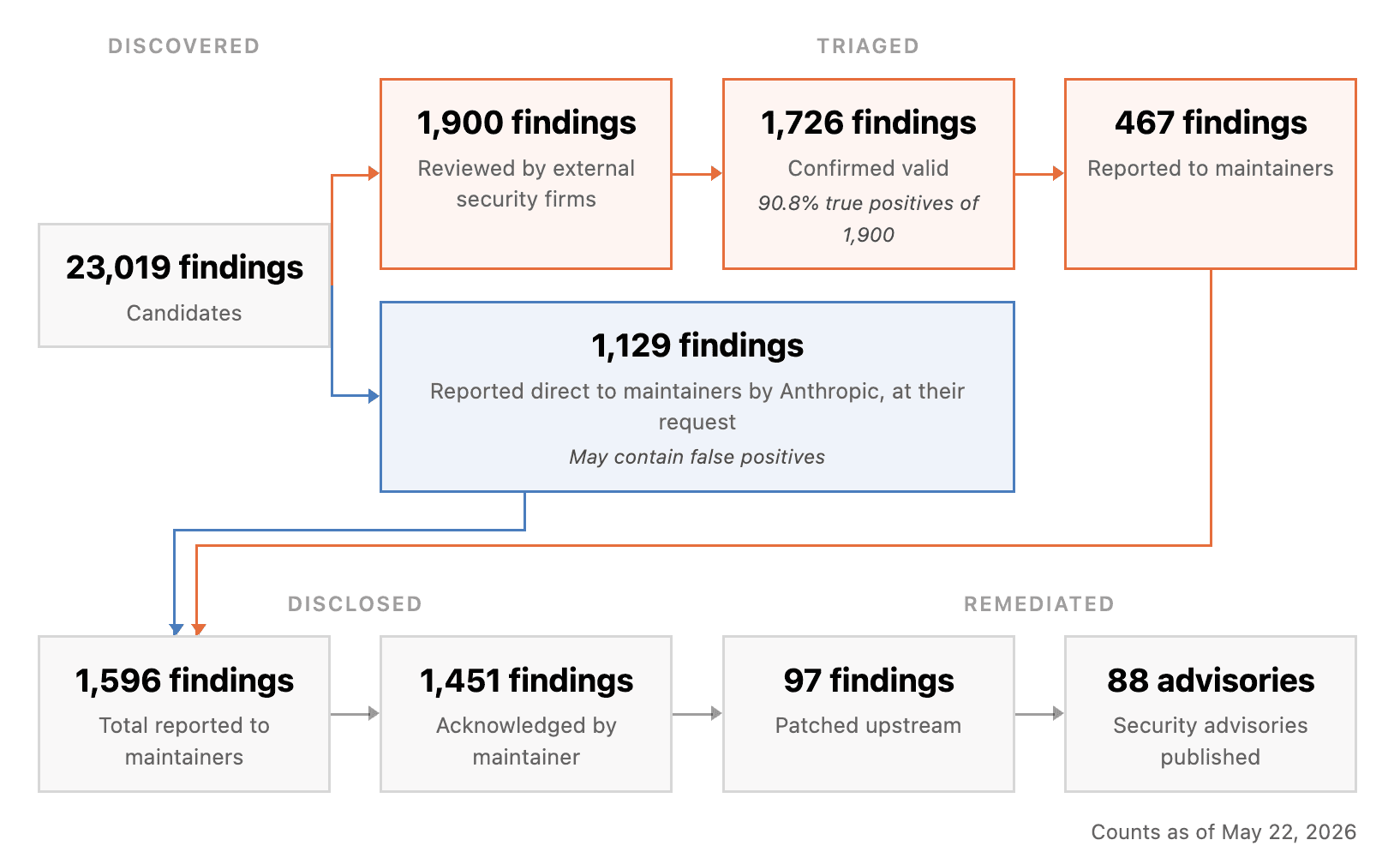
You are not going to staff your way out of this. You are not going to process-improve your way out of it at the margin. The funnel itself has to change.
Speed comes from upstream, not downstream
Before changing anything, measure three things. Most teams have never put numbers on them.
- Time to Validate. From the moment a finding enters your system, how long until you know whether it is exploitable in your environment. Not theoretically vulnerable. Exploitable here, in your stack.
- Time to Remediate. From validation to a verified fix in production.
- Total Exposure Backlog. The volume and age of confirmed-real, unresolved vulnerabilities.
These three tell you where your bottleneck actually sits, and it is rarely where you assume. The rule that follows is simple: the further upstream you intervene, the more leverage you get downstream. If your Time to Validate is two weeks, optimizing patch deployment is rearranging deck chairs.
This is also why we are skeptical of the current rush toward AI auto-remediation. Auto-fix is downstream. It is the most expensive tool you have, it changes production code, and it runs against your full input volume. Triage is upstream, lower risk, and it shrinks the input volume by an order of magnitude before the expensive tool ever runs.
Fix only what is exploitable in your environment. Everything else gets policy and monitoring, not engineering hours. Get triage right first. Then talk about auto-fix.
What we learned building triage that survives an audit
Triage is the lever. But "use AI for triage" is where most teams and most vendors go wrong. Four lessons from building this in production.
Bounded investigations beat clever agents
The instinct, when you start, is to hand the model a CVE and the codebase and say "figure it out." This demos beautifully and fails in production.
Our first version did roughly this. It produced confident verdicts that were sometimes wrong, and worse, that we could not reconstruct a week later. A free-roaming agent wanders, asserts confidence it has not earned, and leaves no trail you can defend.
What works is a per-CVE investigation plan that decomposes the question into bounded, answerable sub-questions. Is the vulnerable function in our dependency graph. Is it reachable from an entrypoint. Are the preconditions for exploitation met in our usage. Is the relevant data flow attacker-controlled. Each sub-question is small and checkable. The output is a verdict plus an evidence trail.
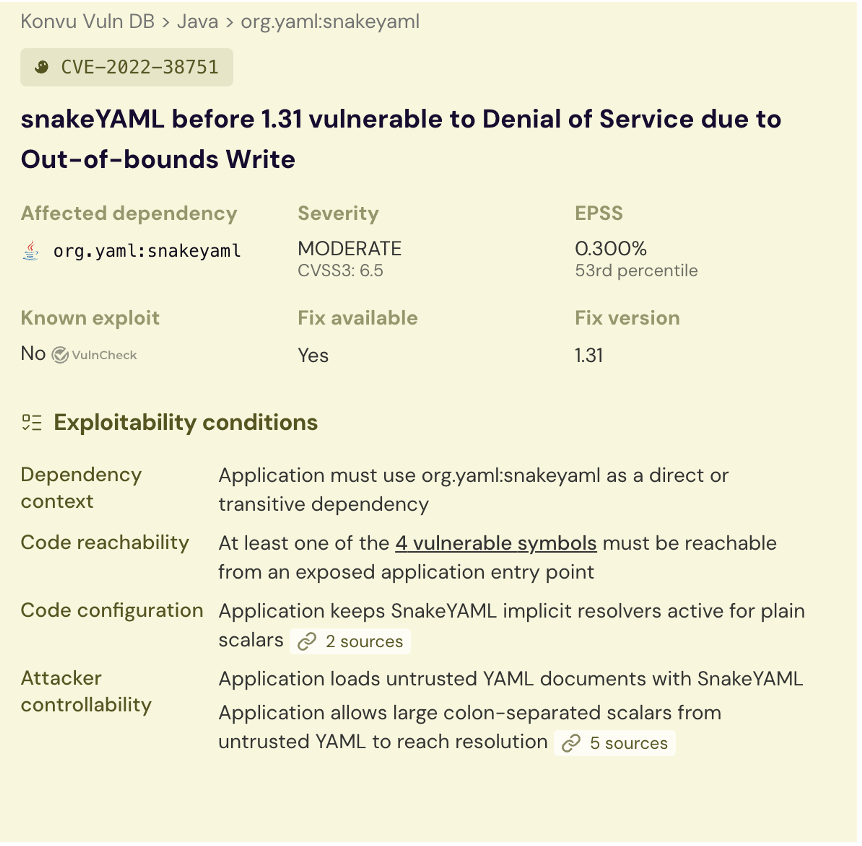
It looks slower than "give it to the model." It is not. It is the only path to reproducible answers, and reproducibility is the prerequisite for everything else.
Draw the line between deterministic and agentic
Two failure modes sit on either side of this.
Wrap a model around your scanner and make everything agentic: nothing is reproducible, and no auditor will accept it. Go deterministic-only and refuse the model any judgment: you cannot synthesize a verdict from raw facts, and judgment is exactly what the model is good at.
The discipline is the boundary itself. Deterministic steps generate the inputs and constraints: SBOM resolution, reachability analysis, version matching, KEV and EPSS lookup, policy evaluation. Run them twice, get the same answer. Agentic reasoning operates on top of those inputs, within bounded scope: exploit feasibility, attacker-control-flow reasoning, mitigation effectiveness.
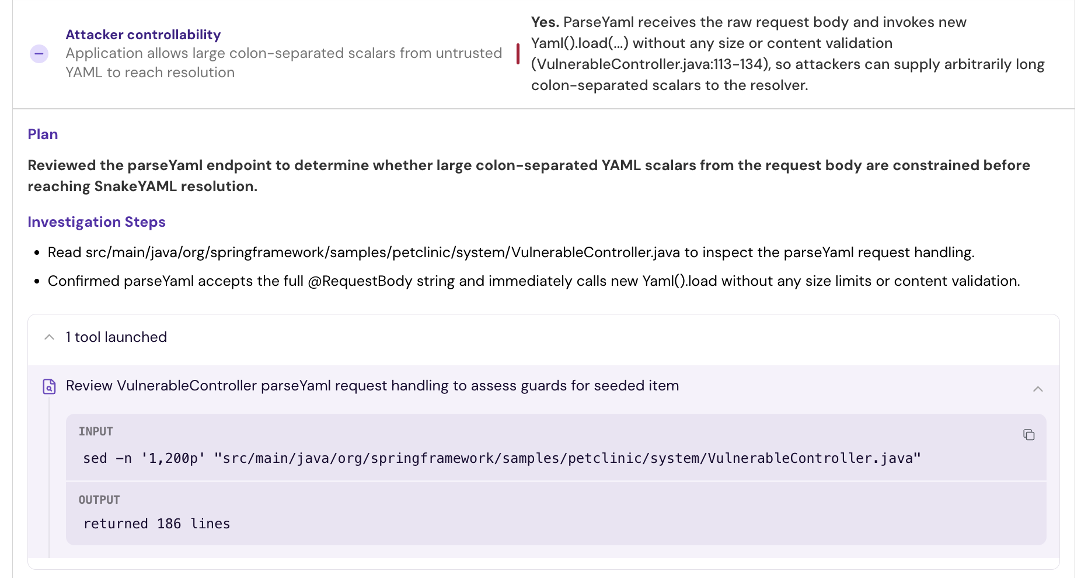
Because the agentic layer is constrained by deterministic inputs, you can run the same finding through the system twice and get the same result. Not because the model is deterministic, but because its scope is. This is also how you answer a regulator. The deterministic layer is your evidence. The agentic layer is your reasoning. Both are inspectable.
Worth saying plainly: reachability is not exploitability. Reachability tells you a function gets called. Exploitability tells you an attacker can actually leverage it in this environment. Different questions, and only the second one should consume an engineer's time. (For a deeper take, see Why static code reachability is not enough.)
Evidence is a first-class output
Most AI triage systems output a verdict. A verdict is not enough.
Every decision has to produce a record that two different audiences can read independently. The engineer reads it to decide whether to act: the specific code path, the preconditions, what would change the verdict. The auditor reads it to decide whether to trust the decision: the inputs it was based on, the policy applied, the system and model versions, the timestamp.
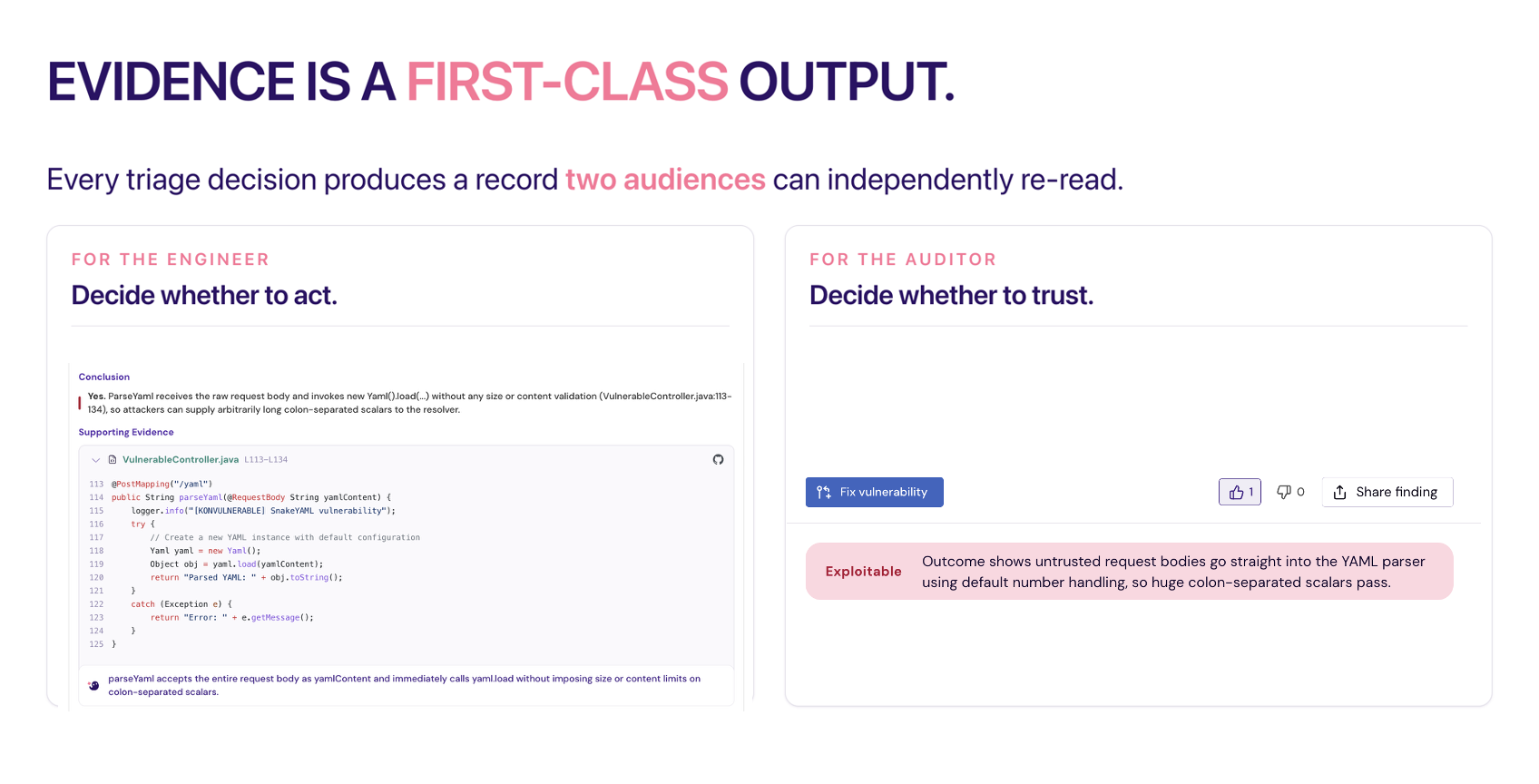
As the EU AI Act's obligations phase in, alongside NIS2 and existing disclosure regimes, "we used AI" stops being a defense. "We used AI, and here is the inspectable record of every decision it influenced" is one. If you cannot reproduce a triage decision a year later, you do not have a vulnerability management program. You have a logging gap with extra steps.
Evaluate the reasoning chain, not the output
All of the above is worthless if you cannot measure whether it works. Evaluating an agentic system is its own problem, and it is not the same as grading a verdict.
The framework we landed on has five layers, running from deterministic to human judgment:
- Necessary failure checks — repo accessible, tools fired, finding IDs match. Deterministic.
- Faithfulness — cited symbols resolve, files were actually read, version strings exist. Deterministic.
- Per-item reasoning — was the evidence sufficient per item, and is each item correct given that evidence. Rubric.
- Global reasoning quality — does the final verdict follow from the per-item answers. Rubric.
- End-to-end audit — does the verdict match a senior security engineer's. Human.
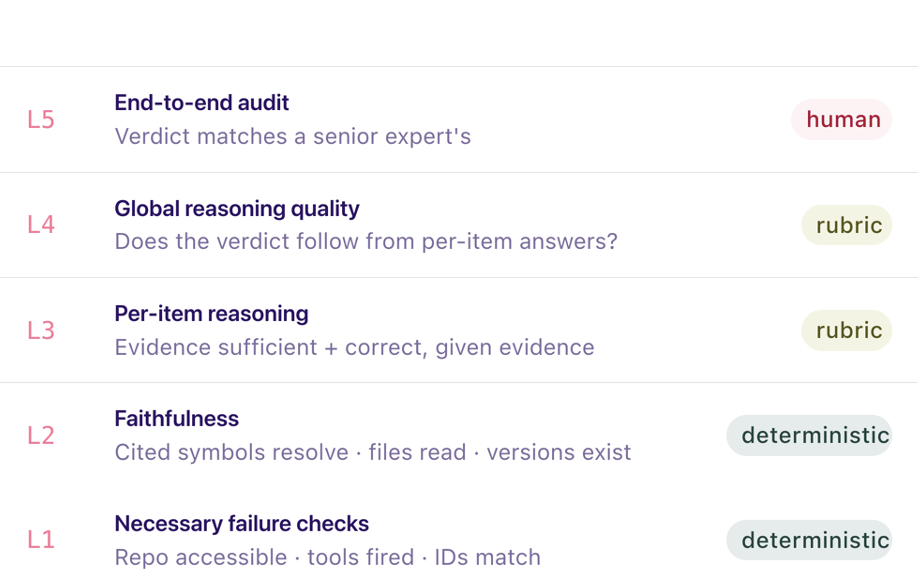
The reframe that mattered for us: you are not grading the output, you are grading the reasoning chain that produced it. "The agent is wrong" is a useless bug report. "The agent fails at layer 4 — its per-item reasoning is sound but its synthesis is not" tells you exactly what to fix.
It has two more benefits. Expert review stops being a thumbs-up that evaporates and becomes structured per-layer signal that compounds. And the same layer structure generalizes across agent types, even as the content of each layer changes.
What attackers don't have
It is easy to read all of this as bad news for defenders. The supply shock is real, the clock is real, the asymmetry is real. But there is one fact the panic obscures.
Attackers now have AI. They do not have ground truth about your environment. Your dependency graph, your runtime context, your deployment topology, your policy, the specific conditions under which a given flaw becomes exploitable in your stack. You have all of that. They have to discover it.
AI on the defender side is uniquely good at applying that internal context at scale, which is precisely the thing attacker-side AI cannot do, because it lacks the inputs. The advantage is already in your hands. The work is in building the function that wields it.
Takeaway
Phil Venables put the era in three words: retool everything for speed. For vulnerability management, speed does not come from fixing faster at the end of the line. It comes from moving the decision upstream, anchoring it in real exploitability, and building an AI triage layer you can actually reproduce and defend.
The flood is coming either way. The question is not whether you can keep up with attackers who now have the same models you do. It is whether you have built the function to use the one advantage they will never have: you know your environment, and they do not.